- 본 포스팅은 'Google Advanced Data Analytics Professional Certificate' 과정을 수강하며 요약/정리하기 위한 포스팅입니다.
Bootstrapping 과 Aggregating 을 통합하여 배깅이라고 한다.
기초 학습자(base learners)들의 앙상블은 강력한 예측 변수가 될 수 있다.
배깅은 부트스트랩의 집합(bootstrap aggregating)을 의미하지만,
이렇게 말할 수 있는 것만으로 배깅 모델을 이해했다고 할 순 없기 때문에 그 의미를 살펴보고자 한다.
Bootstrapping
부트스트래핑(bootstrapping)은 중복 가능하게 샘플링하는 것을 의미한다.
앙상블 모델링 아키텍처에서, 부트스트래핑은 각 기본 학습자에 대해 동일한 관측치를 여러 번 샘플링할 수 있다는 것을 의미한다.
1,000개의 관측치 데이터 세트가 있다고 가정하고,
이를 부트스트랩하여 1,000개의 관측치의 새 데이터 세트를 생성한다면,
평균적으로(확률적으로) 표본 데이터 세트에서 약 632개의 관측치를 포함한다고 예상할 수 있다. (~63.2%).
Aggregating
부트스트랩된 데이터로 단일 모델을 구축하는 것은 그다지 유용하지 않다.
1,000개의 데이터로 부트스트랩 샘플링하면, 새 데이터 세트에서 평균적으로 632개의 고유한 데이터만 포함한다는 것을 의미하고,
이는 368개의 관측치가 새 표본 데이터 세트에 포함되지 않아서 데이터 손실이 발생한다는 것을 의미한다.
앙상블 학습(Ensemble learning)은 여러 모델을 구축하여 예측한 결과를 종합하는 것이다.
물론 이러한 368개의 관측치는 해당 샘플 데이터 세트에 포함되지 않을 수도 있지만,
부트스트랩 프로세스를 각 기본 학습자마다 반복하면,
최종적으로 기본 학습자의 전체 앙상블이 모든 관측치를 포함할 수 있을 것이기 때문이다.
Example: bagging vs. single decision tree
다음은 두 개의 클래스가 포함된 데이터 세트에서 가져온 몇 가지 테스트 데이터이다:

다음은 단일 의사결정나무에 의한 이 테스트 데이터의 예측과,
50개 의사결정나무의 앙상블에 의한 예측을 비교한 것입니다:


X는 잘못된 예측을 나타낸다.
단일 의사결정나무 모델은 60개 중 11개의 예측을 틀렸다. 정확도는 81.7%.
한편, 배깅을 사용한 의사결정나무의 앙상블은 6개만 틀렸습니다. 배깅을 활용 시 정확도가 10% 향상되었다.
이러한 모델의 결과를 검사하는 또 다른 방법은 의사 결정 경계를 표시하는 것이다:

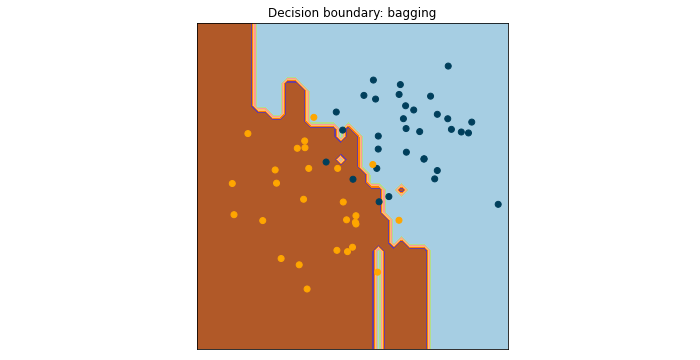
Why to use it (배깅의 장점)
- Reduces variance: 단일 모델의 경우 분산이 높을 수 있다. 베이스 모델의 예측을 앙상블로 종합하면 분산을 줄일 수 있다.
- Fast: 학습은 CPU 코어와 다른 서버 사이에 동시에 이루어질 수 있어서 보다 빠른 학습이 가능하다.
- Good for big data: 배깅은 모델 학습 중에 전체 트레이닝셋을 메모리에 저장할 필요가 없다. 각 부트스트랩의 샘플 크기를 전체 데이터의 일부로 설정하고, 기본 학습자(base learner)를 학습하고, 전체 데이터셋을 한 번에 사용하지 않고 이러한 기본 학습자를 함께 묶을 수 있다.
Resources for more information
More detailed information about bagging can be found here.
- Kaggle lesson on bagging: An in-depth guide to bagging, including worked examples and mathematical intuition
- Academic paper: Leo Breiman’s foundational paper on bagging
- scikit-learn documentation:
'데이터사이언스 > Google Advanced Data Analytics' 카테고리의 다른 글
| 랜덤 포레스트 모델 (Random forest) 하이퍼파라미터 튜닝 팁 + Cheat Sheet (0) | 2023.06.03 |
|---|---|
| Random Forests란 (1) | 2023.06.03 |
| [머신러닝] 분류 모델의 평가 지표 개념 정리 | Accuracy, Precision, Recall, ROC 곡선, AUC, F1점수, F베타점수 (0) | 2023.05.31 |
| 데이터 분석 직무 면접 준비 시 간략한 소감 (0) | 2023.05.27 |
| [머신러닝] 로지스틱 회귀 모형을 해석할 때 주의 사항 (평가 지표 선택 시 어떤 점을 고려해야 할까?) | Precision, Accuracy, Recall 비교 정리 (0) | 2023.05.27 |