- 본 포스팅은 'Google Advanced Data Analytics Professional Certificate' 과정을 수강하며 요약/정리하기 위한 포스팅입니다.
데이터 전문가라면 그래디언트 부스팅을 자주 접할 가능성이 높기 때문에 어떻게 작동하는지 이해하는 것이 중요하다.
그레디언트 부스팅은 모델 앙상블을 사용하여 타겟을 예측하는 지도학습 모델이다. GBM이 트리 기반일 필요는 없지만 일반적으로 트리 앙상블을 사용한다.
트리 기반 그레디언트 부스팅에는 다른 모델링 기법과 차별화되는 두 가지 주요 기능이 있다:
- 의사결정나무 기본 학습자의 앙상블을 구성하여, 각 기본 학습자가 연속적으로 학습하고, 이전 트리의 오류(잔차)를 예측하여 이를 보완한다.
- 기본 학습자 트리는 "약한 학습자(weak learners)" 또는 "결정 스텀프(decision stumps)"로 알려져 있다. 일반적으로 매우 얕다(shallow).
다음은 3개의 나무로 앙상블한 그래디언트 부스팅 수도 코드이다.
learner1.fit(X, y) # Fit the data
ŷ1 = learner1.predict(X) # Predict on X
error1 = y – ŷ1 # Calculate the error → (actual – predicted)
learner2.fit(X, error1) # Fit tree 2, but target = error from tree 1
ŷ2 = learner2.predict(X) # Predict on X
error2 = ŷ2 – error1 # Calculate the new error
learner3.fit(X, error2) # Fit tree 3, but target = error from tree 2
ŷ3 = learner3.predict(X) # Predict on X
error3 = ŷ3 – error2 # Calculate the new error
For these observations and any new samples being predicted by this model:
Final prediction = learner1.predict(X) + learner2.predict(X) + learner3.predict(X)
예제
시나리오: 자전거 도로를 따라 물병을 판매하는 공급업체.
데이터는 판매한 물의 양과 하루의 정오 온도.
목적: 하루의 온도를 기반으로 남자가 얼마나 많은 물병을 팔았는지 예측
| 14 | 72 |
| 17 | 80 |
| 20 | 98 |
| 23 | 137 |
| 26 | 192 |
| 29 | 225 |
| 32 | 290 |
| 35 | 201 |
| 38 | 95 |
| 41 | 81 |
1단계는 데이터에 모형을 적합시키는 것.
예제에서는 온도를 단일 X 피쳐로 사용하고, 판매를 목표 변수로 사용한다.
모델은 GBM이 사용하는 약한 학습자를 복제하기 위해 최대 깊이 1(즉, 한 번만 분할)까지만 증가할 수 있는 정기적인 의사 결정나무이다.
인덱스, 온도, 판매량, 트리1 예측, 트리1 오차, 트리2 예측, 트리2 오차, 트리3 예측, 트리3 오차, 최종예측
| 0 | 14 | 72 | 80 | -8 | 4.5 | -12.5 | -4.5 | -8 | 80 |
| 1 | 17 | 80 | 80 | 0 | 4.5 | -4.5 | -4.5 | 0 | 80 |
| 2 | 20 | 98 | 80 | 18 | 4.5 | 13.5 | -4.5 | 18 | 80 |
| 3 | 23 | 137 | 192 | -55 | 4.5 | -59.5 | -4.5 | -55 | 192 |
| 4 | 26 | 192 | 192 | 0 | 4.5 | -4.5 | -4.5 | 0 | 192 |
| 5 | 29 | 225 | 192 | 33 | 4.5 | 28.5 | 7 | 21.5 | 203.5 |
| 6 | 32 | 290 | 192 | 98 | 4.5 | 93.5 | 7 | 86.5 | 203.5 |
| 7 | 35 | 201 | 192 | 9 | 4.5 | 4.5 | 7 | -2.5 | 203.5 |
| 8 | 38 | 95 | 192 | -97 | -104 | 7 | 7 | 0 | 95 |
| 9 | 41 | 81 | 192 | -111 | -104 | -7 | 7 | -14 | 95 |
데이터에는 온도, 판매된 물병 수, 세 가지 기본 학습자 트리의 예측, 오류 및 각 날짜의 최종 예측을 포함한 정보가 포함되어 있다.
첫 번째 트리는 판매 수를 예측한다. 각 후속 트리는 앞 트리의 오류를 예측한다.
인덱스 0에서 하루를 예로 들어 보면, 판매량은 72개이다.
트리 1은 80을 예측했고. 잔차 오차를 계산하려면 예측값에서 실제 값을 빼면 된다. 이 경우: 72 – 80 = -8.
'-8' 은 "트리 1 오차" 열의 값입니다.
다음 트리(트리 2)는 트리 1의 오차를 예측한다.
최종 예측은 세 가지 트리의 예측 합계를 나타낸다. 인덱스 0에 있는 날의 경우 80 + 4.5 – 4.5 = 80이다.
다음은 과정의 각 단계에서 판매되는 예측 판매 개수 대 실제 판매 개수를 나타내는 몇 가지 그림이다.

첫 번째 그래프에서 X는 실제 판매된 물병의 수를 나타내고, 보라색 점은 예측된 수를 나타낸다.
점들을 연결하는 선의 각 수직 부분은 모형의 분할 또는 결정 경계를 나타낸다.
단일 트리의 경우 수직선은 하나뿐이다. 한 번만 분할되기 때문이다.
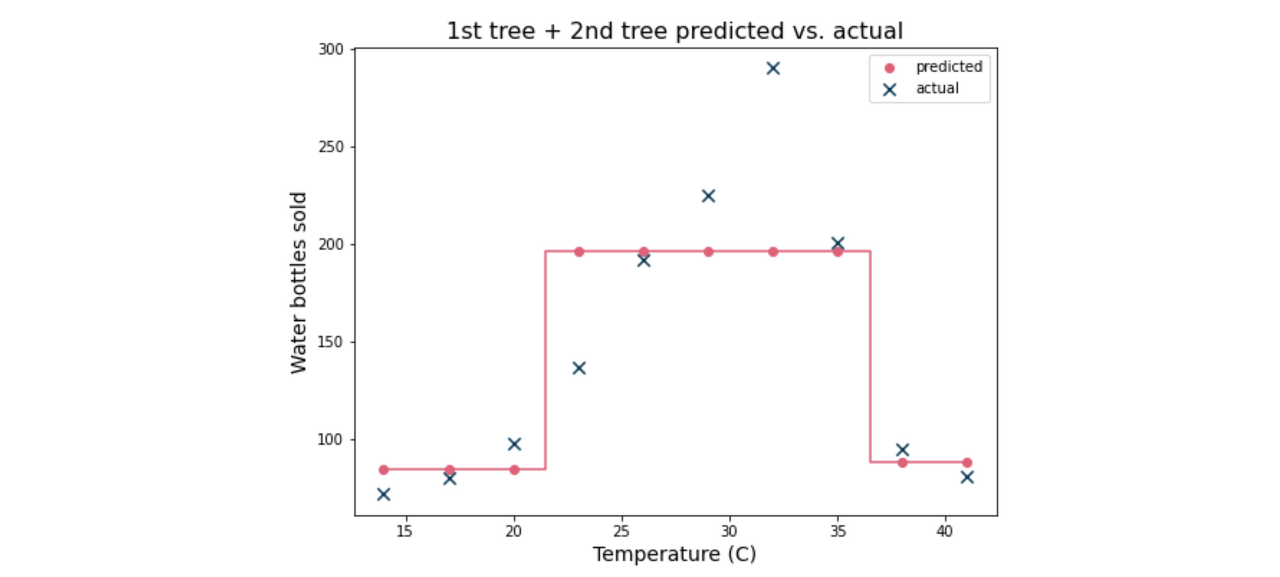
다음 그래프는 처음 두 트리 대 실제 값의 예측을 보여준다.
각 예측 지점은 첫 번째 트리와 두 번째 트리의 예측 합계를 나타낸다.
예측은 실제 값과 더 밀접하게 일치하지만 모형은 여전히 데이터에 적합하지 않는다.

세 개의 나무가 예측하는 것을 그래프로 보여준다.
각 기본 학습자가 추가되면 최종 예측에 더 많은 뉘앙스(성질?)가 추가된다.
즉, 의사 결정 경계(여기서 노란색 선의 수직 세그먼트로 표시됨)가 추가되어 예측이 더 정확해질 수 있다.
이 경우 모든 표본은 네 개의 다른 값 중 하나에 할당되는 반면, 이전 예제에서는 모든 표본이 세 개의 다른 값 중 하나에 할당되었다.
다음은 30개의 트리에 대한 예측 곡선:
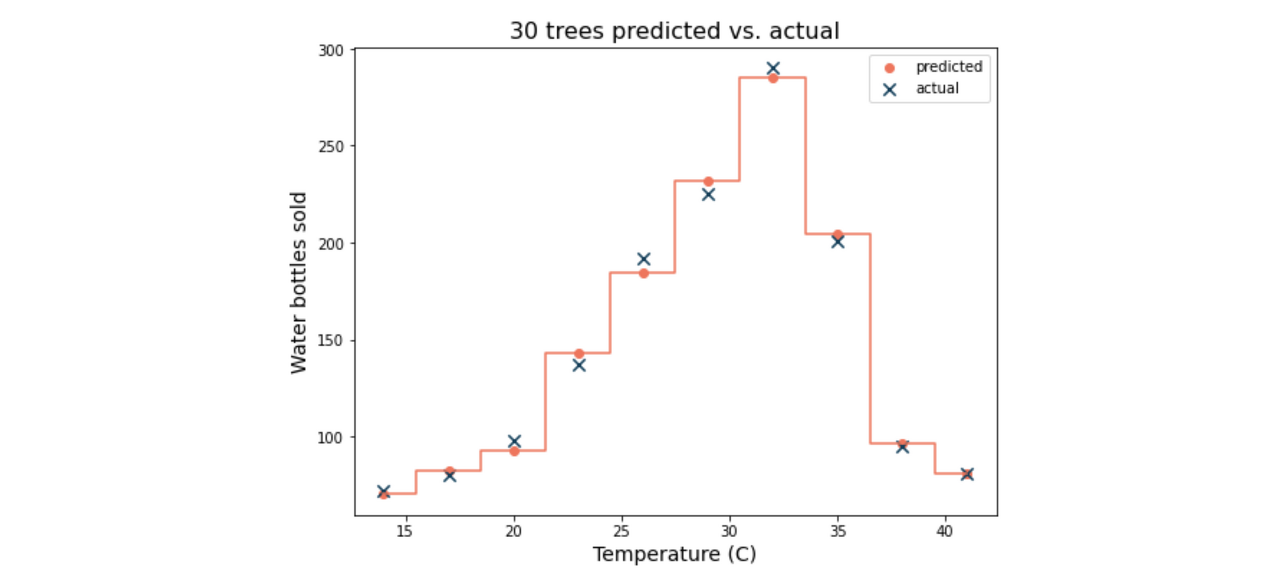
이 모델 앙상블의 예측 값은 표본의 실제 값과 매우 밀접하게 일치한다.
그러나 완벽한 예측은 아니다.
사실 하나의 의사 결정 나무가 5개의 깊이로 증가하도록 허용된다면, 이 데이터를 완벽하게 맞출 수 있다.
그러나 그레디언트 부스팅과 같은 앙상블 방법의 장점은 단일 의사 결정 나무보다 데이터가 과적합될 가능성이 적다는 것이다.
Key takeaways
그레디언트 부스팅은 약한 학습자의 앙상블을 사용하여 최종 예측을 하는 간단하면서 강력한 예측 기술이다.
GBM models are more resilient to high variance that results from overfitting the data due to being comprised of high-bias, low-variance weak learners.
The bias of each weak learner in the final model is mitigated by the ensemble.
추가자료:
More detailed information about XGBoost can be found here:
'데이터사이언스 > Google Advanced Data Analytics' 카테고리의 다른 글
| 프로젝트를 포트폴리오화 시키기 위해서 | Github README 파일 작성 팁, 포트폴리오 예제 (0) | 2023.06.19 |
|---|---|
| XGBoost 모델 하이퍼파라미터 튜닝 팁 (0) | 2023.06.04 |
| 랜덤 포레스트 모델 (Random forest) 하이퍼파라미터 튜닝 팁 + Cheat Sheet (0) | 2023.06.03 |
| Random Forests란 (1) | 2023.06.03 |
| [머신러닝] Bagging(배깅)이 모델 학습에 자주 쓰이는 이유와 원리 설명 | Bootstrapping + Aggregating (0) | 2023.06.03 |